En mars 2023, Noam Chomsky écrivait dans le New York Times : « Chat-GPT fait preuve de quelque chose comme la banalité du mal : plagiat, apathie, évitement […]. Ce système offre une défense du type “je ne fais que suivre les ordres” en rejetant la responsabilité sur ses créateurs ».


Abonnement Élucid
Chomsky soutient que le robot conversationnel ne peut faire preuve d’humanité, car il lui manque une capacité essentielle au langage humain : celle d’être normative. C’est la possibilité pour un humain d’inférer ou de produire des règles complexes à partir d’un très petit nombre d’exemples, ou encore d’avoir une réflexion morale, qui serve de fondement éthique à l’action.
Chat-GPT procède de la manière inverse : la méthode de l’automate est « prédictive », au sens où elle génère des phrases à partir d’un immense corpus de données textuelles piochées sur Internet. Les « IA génératives », automates de génération de texte et d’images, seraient donc des « plagiaires » volant le travail des autres. Au vu de leurs conditions de production, la question de l’exploitation du travail et de l’expropriation des données mérite d’être posée sérieusement.
De faux problèmes et de belles histoires…
L’intelligence artificielle est autant une technique qu’une mythologie, c’est-à-dire un ensemble de représentations plus ou moins incantatoires. Ce mythe est alimenté par un discours cherchant, en gros, à imposer l’idée que l’IA va nécessairement continuer de se développer, s’autonomiser, puis évincer progressivement les humains en devenant meilleure qu’eux dans tous les domaines. Un ingénieur chez Google, Blake Lemoine, avait ainsi proclamé en juin 2022 que l’un des modèles conversationnels sur lesquels il travaillait était désormais doué de conscience. Il a été licencié par son employeur suite à ces déclarations.
C’est pourtant une rengaine qui apparaît dès les années 1950 avec ELIZA, le premier agent conversationnel, conçu par Joseph Weizenbaum. Il avait déjà à l’époque mis en évidence la tentation d’humaniser les robots ; ELIZA procédait pourtant de manière rudimentaire, en retournant les phrases de ses interlocuteurs à la forme interrogative. Et pourtant, plusieurs de ses utilisateurs avaient commencé à lui attribuer une conscience, donnant naissance à l’« effet ELIZA », soit la tentation d’anthropomorphiser la machine.
Tout cet imaginaire occupe beaucoup de place dans les débats publics. Dans une lettre ouverte demandant un moratoire de six mois sur l’IA signée entre autres par Elon Musk, les inquiétudes qui taraudent les techno-solutionnistes sont détaillées :
« Les systèmes d’IA avec une intelligence pouvant rivaliser avec les hommes peuvent poser des risques profonds à la société et à l’humanité, comme cela a pu être démontré par des recherches poussées et reconnues par les laboratoires d’IA les plus en avance. […]
Les systèmes d’IA contemporains sont désormais en mesure d’entrer en compétition avec les humains pour des tâches générales, et nous devons désormais nous demander : devrions-nous laisser les machines inonder nos canaux d’information avec de la propagande et des contre-vérités ? Devrions-nous automatiser tous les métiers, y compris ceux qui sont épanouissants ? Devrions-nous développer des esprits non-humains qui pourraient un jour être plus nombreux, plus intelligents que nous, qui pourraient nous rendre obsolètes et nous remplacer ? Devrions-nous risquer de perdre le contrôle sur notre civilisation ? »
Sundar Pichai, PDG de Google, déclarait à son tour récemment que les progrès de l’intelligence artificielle étaient inéluctables :
« La révolution de l’intelligence artificielle est au centre d’un débat qui va de ceux qui espèrent qu’elle sauvera l’humanité à ceux qui prédisent un désastre. Google est quelque part au milieu du côté optimiste, introduisant l’IA par étapes pour que la civilisation puisse s’y habituer ».
Comme une course à l’armement, tous les entrepreneurs de l’IA se lancent pour devenir les premiers à proposer une solution exploitable qui leur permettra de s’imposer comme l’acteur incontournable. Ce faisant, ils transforment leur prédiction en prophétie auto-réalisatrice : puisqu’une « IA surpuissante » doit advenir, autant être celui qui l’a créée pour en tirer profit.
L’annonce de ces catastrophes futures devient finalement une stratégie publicitaire : les risques de désinformation, de remplacement de centaines de millions de travailleurs, voire la survie de l’humanité, servent à faire du placement de produit. Si Chat-GPT peut remplacer les journalistes, si Midjourney et Dall-e peuvent remplacer les professions graphiques et visuelles, alors n’est-ce pas une bonne idée d’acheter une licence ? Déjà, nombre de médias font usage de l’un ou de l’autre, qui permettent d’économiser les « coûts » de la main-d’œuvre.
…pour cacher les problèmes concrets et les histoires vraies
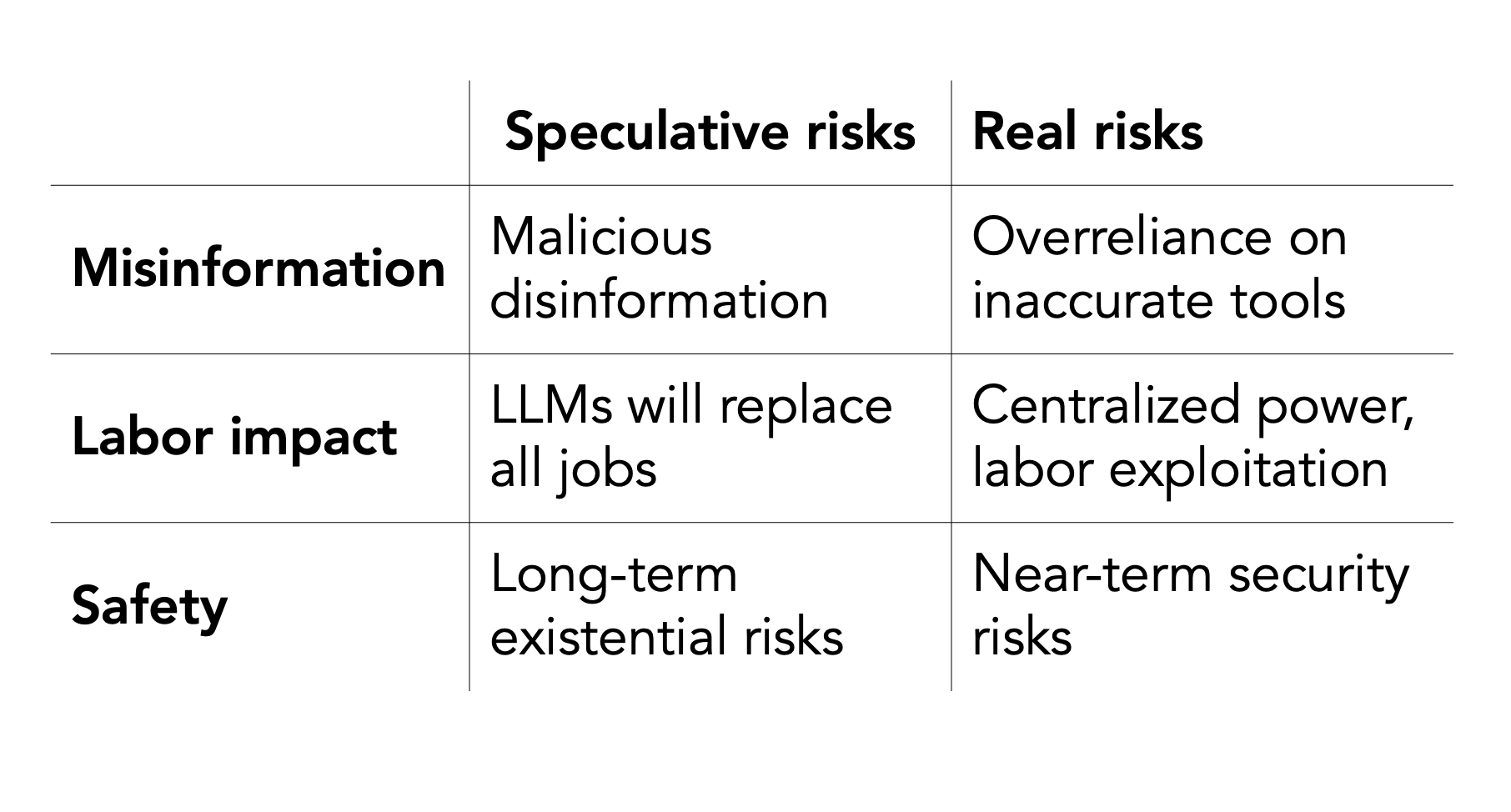
En réaction à cette lettre ouverte, les chercheurs Sayash Kapoor et Arvind Narayanan publient un article expliquant que tous ces dangers sont hautement « spéculatifs » et détournent l’attention des risques et des enjeux immédiats liés aux IA génératives. Pour eux, les véritables enjeux se situent ailleurs :
« Les LLM [Très grands modèles de langage] ne sont pas entraînés pour générer la vérité ; ils génèrent des affirmations plausibles. […] Les outils de l’IA vont faire perdre du pouvoir aux travailleurs et le centraliser entre les mains d’un petit nombre d’entreprises. […] Des assistants fondés sur des LLM pourraient être hackés pour révéler des données personnelles […] éteindre des systèmes, ou faire surgir des vers informatiques qui se déploient sur Internet à travers des LLM. »
Leur position rejoint celle de Timnit Gebru, qui dirigeait une équipe spécialisée dans « l’éthique » de l’IA chez Google, jusqu’à son licenciement en 2020. Elle avait publié un article de recherche qui étudiait les risques environnementaux et financiers des grandes bases de données, et questionnait les méthodes de collecte servant à entraîner les « modèles de langage », c’est-à-dire des agents conversationnels comme Chat-GPT. Elle réagit à son tour fin mars :
« Ces risques hypothétiques sont au centre d’une idéologie dangereuse appelée le long-termisme, qui ignore les dégâts réels résultant du déploiement de systèmes d’IA aujourd’hui. Cette lettre ne répond à aucun des dégâts que continuent de produire ces systèmes, ce qui inclut 1) l’exploitation des travailleurs et le vol massif de données pour créer des produits qui profitent à une poignée d’entités, 2) l’explosion de médias synthétiques dans le monde, qui à la fois reproduit les systèmes d’oppression et met en danger notre écosystème d’information, et 3) la concentration du pouvoir entre les mains d’un petit nombre de personnes qui exacerbe les inégalités sociales. »
La longue-vue serait donc pointée dans la mauvaise direction : les problèmes concrets posés par le déploiement de l’intelligence artificielle sont déjà là. Et les Agences de Protection des Données Européennes commencent à être d’accord sur ce constat.
Cela commence avec le Garante per la Protezione dei Dati (GPDP) en Italie fin mars 2023. La décision de l’autorité italienne avait fait du bruit, car elle enjoignait à OpenAI, l’entreprise produisant l’assistant conversationnel, de se mettre en conformité avec la réglementation européenne. En cause, un bug permettant d’accéder à l’historique des conversations d’autres utilisateurs.
OpenAI décide alors, dans une stratégie de victimisation, de suspendre l’accès à son service en Italie. Mais le mal est fait : le GPDP est bientôt suivi par la CNIL et par l’agence espagnole. En avril, une équipe européenne est créée spécifiquement pour travailler sur le dossier Chat-GPT. La question de la protection des données commence donc à émerger dans le débat, et avec elle, une autre, dont les enjeux économiques sont de taille : celle de la propriété des données.
Les travailleurs du clic et l’expropriation de la donnée
Le travail du régulateur se fait attendre : l’AI Act en Europe est toujours en discussion, et propose une approche « par les risques ». Aux États-Unis, les agences de régulation ont récemment publié un « appel à commentaires », qui annonce l’élaboration de futures règles encadrant le déploiement des IA. Mais ces initiatives ne semblent pas aborder pour l’instant la question des ressources et du travail nécessaires à la production d’IA génératives : à savoir, des données en très grandes quantités, et des « petites mains » pour la rendre utilisable, ceux qu’on appelle les travailleurs du clic ( 1 ).
Le sujet était pourtant mis sur la table par la revue Time en février 2023. Un article ayant connu un retentissement considérable révélait que Chat-GPT rémunérait des modérateurs au Kenya moins de deux dollars de l’heure à « nettoyer » les échanges des utilisateurs avec l’agent conversationnel. L’existence de ces travailleurs rappelle que l’Intelligence artificielle telle que nous la connaissons est « supervisée », comme les moteurs de recherche, et comme les réseaux sociaux, elle nécessite des adjoints humains dont le travail est déprécié et rendu invisible, car il remet en question le mythe de la machine autonome.
Or, Chat-GPT ne se contente pas d’exploiter des travailleurs et ses utilisateurs (car toute interaction est transformée en donnée servant à l’entraîner – jusqu’à ce que la discussion soit fermée). Les IA génératives accaparent également de grandes quantités de données sans demander l’autorisation de les exploiter aux ayants droit.
Ce phénomène qui est davantage visible lorsqu’on s’intéresse aux générateurs d’images, car il génère des conflits avec le droit d’auteur. En janvier 2023 par exemple, plusieurs actions en justice sont lancées aux États-Unis contre Stability AI, Midjourney et Deviant Art. L’un des cabinets d’avocats responsables de ces plaintes écrit :
« Stable Diffusion est une intelligence artificielle produite par StabilityAI, DeviantArt, et Midjourney parmi leurs produits d’IA d’imagerie. Elle a été entraînée sur des milliards d’images protégées par le droit d’auteur, contenues dans la base de données LAION-5B, qui ont été téléchargées et utilisées sans compensation ou consentement des artistes.
Si Stable Diffusion et des produits similaires sont autorisés à opérer comme ils le font aujourd’hui, le résultat prévisible est qu’ils remplaceront les mêmes artistes dont les œuvres dérobées donnent vie à ces produits d’IA avec lesquels ils se retrouvent en compétition. »
Contrairement aux droits numériques et à la protection des données, le droit d’auteur et la propriété intellectuelle sont des régimes avec une longue histoire et défendant des intérêts puissants. L’entreprise Getty Images par exemple, en s’apercevant que les images « créées » par Midjourney généraient parfois le logo Getty, a porté plainte à son tour en début d’année.
Les artistes indépendants cherchent désormais eux aussi à protéger leurs productions. Des sites comme "haveibeentrained.com" sont apparus, qui permettent de consulter les bases d’images les plus connues. Cela permet d’exercer un droit de retrait ; mais il est souvent déjà trop tard, et cela n’empêche pas les entreprises moins scrupuleuses de ne tenir aucun compte de ces requêtes. Des contre-propositions techniques commencent également à émerger, comme l’application Glaze, qui permet d’altérer les images afin de les rendre « indigestes » pour les IA.
C’est également visible pour les modèles de langage. Le Washington Post publiait en avril une analyse de la base de données (ouverte) C4 de Google, recensant les 15 millions de sites qui la composent. Les journalistes ajoutent :
« Bien que C4 soit énorme, les très grands modèles de langage utilisent probablement des bases de données encore plus gargantuesques, disent les experts. Par exemple, les données d’entraînement pour GPT3 d’OpenAI, publiées en 2020, ont commencé avec l’équivalent de 40 fois la quantité de données récupérées du web dans C4. »
Déjà, des sites comme Stack Overflow et Reddit commencent à exiger des rémunérations pour des contenus extraits de leurs pages servant à entraîner des intelligences artificielles. Mais ce transfert de revenus éventuels s’arrête au fournisseur de service, non au producteur de contenu ; les utilisateurs, qui alimentent ces sites ne sont pas inclus dans ces éventuels arrangements.
C’est un transfert de propriété qui ne se fait donc pas sans accroc. Mais le plus probable est que ces disputes entre « gros » soient réglées à l’amiable, en passant des accords d’exploitation et de rémunération de ces bases de données. Les individus spoliés auront, eux, beaucoup plus de mal à faire valoir leurs droits. C’est en fait une forme d’expropriation qui se déroule à bas bruit, et qui concerne toutes les productions publiées sur Internet qui ne seraient pas protégées. Le chercheur Olivier Ertzscheid écrivait à ce propos sur son blog, en février 2023 :
« Ce dont nous sommes également sûrs, c’est que la facilité et la gratuité d’aujourd’hui auront tôt fait de se transformer en licences d’usage plus ou moins coûteuses. Ce dont nous sommes sûrs encore, c’est que l’articulation de ces créations au régime du droit d’auteur ne se fera ni sans heurts ni sans passionnants débats. […]
Ce dont nous sommes sûrs enfin, c’est que les chaînes de décision et de responsabilité vont comme à chaque avancée numérique majeure, continuer de se diluer et si nous n’y prenons garde, de se déliter. Qui est responsable de la génération elle-même, mais aussi du statut publiable et diffusable de celle-ci ? Celui ou celle qui a tapé le “prompt” ? Le propriétaire – s’il y en a un – de la base d’images l’ayant permis ? Celles et ceux qui ont programmé et réglé l’algorithme utilisé pour la génération ? Celles et ceux qui ont constitué et travaillé sur les jeux de données (datasets) sans lesquels il n’y aurait pas de génération possible ? »
La machine contre le travailleur
« C’est assez fascinant », dit Bruno Le Maire, ministre de l’Économie, à propos de Chat-GPT, qui lui aurait produit « en cinq minutes » un discours qu’il aurait mis « trois ou quatre heures à écrire ».
Reprenant ce commentaire, le journaliste Romaric Godin écrit : « Dire qu’il est capable de produire un discours sur la Chine que pourrait prononcer Bruno Le Maire n’est pas réellement la preuve d’une créativité et d’un apport majeur à la production de contenu ». Il précise surtout la chose suivante : si les outils numériques servent à intensifier le travail et à augmenter la surveillance, tout reste à prouver en termes de gains de productivité, et donc de hausse des taux de profit.
C’est donc la recherche de débouchés « productifs », qui pousse une équipe de chercheurs à écrire que Chat-GPT pourrait remplacer les travailleurs des plateformes chargés de superviser et d’annoter les données. L’association de soutien aux travailleurs de la plateforme Amazon Mechanical Turk – spécialisée dans les « micro-tâches » – répond :
« Le langage est une chose vivante, qui respire. Un programme informatique ne va pas vérifier dans le monde réel ce qu’il a récolté sur Internet. De manière similaire, Chat-GPT peut générer du texte, mais un humain doit encore le lire pour décider s’il s’agit d’un “bon” texte. Avec tout l’emballement autour du remplacement d’écrivains, d’annotateurs de données et d’artistes par Chat-GPT, il faut nous rappeler qu’écrire et connaître, ce n’est pas juste poser des mots ou assigner des catégories, cela porte aussi sur le jugement. »
L’histoire des IA est aujourd’hui celle d’une dépossession en amont, d'une perte de contrôle des données et de leur transformation en matière exploitable. En aval, elle signale aussi une fragilisation des droits des travailleurs. La banque d’affaires Goldman Sachs, par exemple, dans un dossier publié récemment, expliquait que les IA génératives pourraient faire disparaître 300 millions d’emplois dans un futur proche.
Cette affirmation fait écho à l’article « The Future of Employment » des chercheurs Michael Osborne et Carl Benedikt Frey. Ce « document de travail » publié en 2013 avait fait grand bruit : il déterminait que 47 % des emplois aux États-Unis étaient susceptibles d’être remplacés avant 2025 par l’automatisation. Des proportions similaires étaient mentionnées pour la France.
Nous le savons désormais, ce « grand remplacement » robotique n’a pas eu lieu. En revanche, la publication de ces études, dans le sillage desquelles ondulent une myriade d’articles de presse, constitue une pression supplémentaire pour les travailleurs.
Mis en compétition avec des machines qui travailleraient plus vite pour moins cher – et qui sont issues des données qu’ils ont produit eux-mêmes – les travailleurs en col blanc se trouvent, comme auparavant les cols bleus, mis sous pression pour justifier le « coût » de leur travail. En réalité, cette stratégie n’a rien de nouveau : Uber avait dès son lancement prévu de collecter les données de géolocalisation de ses chauffeurs pour servir de base à un service entièrement automatisé, une flotte de véhicules autonomes. Un rêve – très – lointain pour le moment.
La lutte des classes au XXIe siècle
L’une des grandes questions qui se posent est celle de la propriété des biens numériques et des données. Les gigantesques bases de données à l’origine des IA génératives qui sont en train d’apparaître constituent désormais plus qu’une matière première, elles sont transformées en capital qui peut générer d’importants revenus.
Similaire au chalutage de fond, cette méthode de pêche consistant à déployer de gigantesques filets pour tout ramasser sur son passage, la collecte massive des données plus ou moins publiques préfigure un futur inquiétant pour le monde numérique. Les usagers et les organisations avertis tenteront de se défendre de ces formes d’expropriation comme ils le peuvent, quitte à multiplier les barrières d’accès sur Internet.
L’intelligence artificielle, une fois qu’on s’intéresse à la façon dont elle est produite, devient alors très clairement un enjeu de rapport entre capital et travail. L’économiste Michael Roberts écrit ainsi sur son blog, citant le Grundrisse de Karl Marx :
« Dès que la machine a libéré une partie des travailleurs employés dans une certaine branche de l’industrie, la réserve d’hommes est aussitôt redirigée dans de nouveaux canaux d’emploi et absorbée dans d’autres branches ; entre-temps les victimes originelles, pendant la période de transition, pour la plupart crient famine et périssent.
L’implication ici est que l’automation signifie davantage de boulots précaires et un accroissement des inégalités. […] Ce n’est pas une coïncidence que des entreprises comme Google emploient moins d’un dixième du nombre de travailleurs que de grandes entreprises, comme General Motors, employaient par le passé. Ceci est une conséquence du modèle économique de la Big Tech, qui est fondé non sur la création d’emplois, mais sur son automatisation.
C’est cela, le modèle économique de l’IA sous le capitalisme. Mais dans le cadre de moyens de production automatisés collectivisés, il existe de nombreuses applications de l'IA qui pourraient augmenter les capacités humaines et créer de nouvelles tâches dans les domaines de l'éducation, des soins de santé et même de l'industrie manufacturière. »
Photo d’ouverture : Logos d'OpenAI et de ChatGPT, 23 janvier 2023 - Lionel Bonaventure - @AFP
Cet article est gratuit grâce aux contributions des abonnés !
Pour nous soutenir et avoir accès à tous les contenus, c'est par ici :
S’abonner
Accès illimité au site à partir de 1€
Déjà abonné ? Connectez-vous







2 commentaires
Devenez abonné !
Vous souhaitez pouvoir commenter nos articles et échanger avec notre communauté de lecteurs ? Abonnez-vous pour accéder à cette fonctionnalité.
S'abonner